Nora is an English-Spanish translator, expert back-translator, localizer, proofreader, quality manager, and linguistic validation consultant. She holds a B.A. in Translation with a Major in Law from the University of Buenos Aires, and has been in the translation industry for over 30 years now. Initially an in-house translator for the largest publicly-held bank in Argentina and a classroom-based and distance-education Teacher of English for International Trade, she became a freelance translator in 1992. Nora was Vice-President of FairTradeNet, a Geneva-based association of freelance translators and, as such, was part of the delegation representing FTN at the World Summit on the Information Society in December 2003. She became a certified life-sciences linguist in 2007 and is currently co-owner of Translartisan, a translation studio specializing in biomedical translation. You can find her on Facebook [facebook.com/translartisan], Twitter [@translartisan], Pinterest [pinterest.com/translartisan], LinkedIn [linkedin.com/in/noratorres], or contact her through her website [translartisan.com].
If your job involves IT localization (e.g., localizing apps used in clinical trials), you may have been using the Microsoft Language Portal since as early as 2009.
The Portal used to host a multilingual online dictionary “designed to enable individuals and communities around the world to interact with each other and with Microsoft’s language specialists on matters related to computer terminology”. It also offered free downloads of localization style guides and translations of user interface text.
BUT it was removed on June 30 this year, in what seemed to be a sad end to the story.
The goods news is that, on June 29, the Microsoft Learn website announced where the Microsoft Language Resources (Terminology, UI Strings, Localization Style Guides, and Regional Formats) would be moved to.
Microsoft Terminology, which can serve as a base IT glossary for language development in the nearly 100 languages available, can be queried via the Microsoft Terminology Search page.
Microsoft terminology is also provided in .tbx format, an industry standard for terminology exchange, for download.
I started reviewing other people’s translations and having mine reviewed by others about thirty years ago, while working at the translation department of a major public bank in my country, Argentina.
We used to translate financial agreements and bank-related stuff mostly, but legal papers and different types of technical texts as well, including patents and manuals.
We worked the old-fashioned way– face to face, in groups of three or four, on “real” pieces of paper, using “real” black pens. There weren’t any computers, Internet resources or electronic dictionaries. No translators’ fora on which to ask “difficult” questions. No CAT tools or translation memories to share. No DTP resources either, just simple, ordinary typewriters.
There was, yes, a wonderful collection of dictionaries in the office, and, when our own resources failed to fit the bill, there was the possibility of browsing the well-provisioned library of the Ministry of Economy, just two blocks away, crossing the sadly famous Plaza de Mayo Square, and the U.S. Lincoln Library (at the time located on Florida Street, about a block away from Plaza San Martín).
We used to have hot discussions over the meaning of a word, over the convenience of using one grammatical structure or another, over whether we were respecting the original or not… until we would come to an agreement (or go with the majority opinion).
Sometimes, all this was not enough and there was the need to ask for expert advice. So, depending on the nature of the translation, we would resort to people from the Legal Department, the Project Development Team or Architectural Services, for example, and we would pester them with questions and doubts, paper and pencil in hand.
The pile of paper sheets would grow over days… or weeks. And a glossary for the whole project would be developed at the same pace. There being no word processors, we had to go back and forth uncountable times in our manuscripts, making corrections here and there, when we finally found out the meaning of those problem words that repeated themselves all over the translation.
Then, each of us would check his or her own translation against the original for accuracy and completeness, make consistency adjustments, and correct any spelling mistakes (spell-checkers in 30 languages were still science fiction). Finally, we would put all the pieces together and hand them to the lucky one who would review the whole thing.
My first reviews taught me a lot about my colleagues’ personality and particular ways of approaching a translation– the extent and success of their research efforts, their ability (or inability) to keep consistency in a long text and to maintain attention to detail after long hours of work, the swiftness with which they would take things for granted… I felt at the time, and I still feel today, that such a “dissection” of someone else’s work is a unique opportunity to see how other people work, how they organize their thinking and work, how much they understand and like (or dislike) a certain text and the translation task in general.
Whether it was me or someone else in the team that reviewed the group’s work, we always followed not only an established working procedure but also certain “good fellowship” criteria. We had our differences, but, in essence, we were all friends. And were there to help each other do the best possible job.
Today, I don’t have the opportunity of being part of “physical teams” as I did in the past. I work with e-colleagues from distant places in the planet, and I somehow miss the closeness I shared with my old workmates. But the lessons I learnt while working with them will always stay with me…
#1 – I always respect the original translation. I may like it or not, I might have done the whole thing quite differently, but if the translation is correct, I leave it as it is. (In some cases, I write comments on how I’d have solved a certain problem posed by the source text, and many translators have been grateful for these.)
#2 – I never undertake to review a text when I’m not familiar with the subject matter. In a similar fashion, I try to have my translations reviewed by the “right” people.
Some time ago, I was asked to bid for the translation into Spanish of some mutual fund reports. I had to translate a sample text, which was short but full of twists and turns. I immediately called Javier, a good old friend of mine, who’s an expert in stock markets and mutual funds and, on top of that, a very good translator. I translated the sample and sent it over to him for revision– an hour later, when I got the text back, I couldn’t recognize it. Not that he had changed “my style”, but apparently I had chosen all the “wrong” terms. I submitted the translated sample rather dubiously… but they happily gave us the job. Javier and I worked together for the following month. Every time I finished two or three of the reports, I forwarded them to him. I’d receive them back the following day, all red-marked at the beginning. In the course of the month, I learnt a lot about that specific terminology and, by the end of it, Javier just had to make minor adjustments to my texts. We would discuss, argue and even quarrel, but finally came to agreements. It was kind of stressing, but everything went just fine.
#3 – Whenever possible, I reserve the right to have my translations reviewed by people I like and respect, people who will respect my work but who won’t overlook my mistakes, whether big or small. If, after working once or twice with somebody, I find out that he or she is not the “right one” for me, I just won’t ask them again.
In short, the relationship between translator and reviewer should be based on trust, friendship and genuine teamwork. And, of course, “genuine teamwork” is not possible when the translator feels the reviewer is out there to criticize and prove his or her point, and not to help out.
Translation inaccuracies, failure to figure out ambiguities and to understand context in creative language, inability to successfully communicate nuances of meaning, and lack of cultural awareness are not the only cons of machine translation. The use of online MT also involves a risk of disclosure of sensitive information.
It seems to me MT should be understood strictly as a tool, and be used as such. A tool to facilitate our work. A tool, just like the many others we use on a daily basis.
Whatever your take may be on this issue, though, you may want to know how MT developed. The post below, amazingly researched and written by Vasily Zubarev (Python developer, NLP specialist, blogger), and reblogged here with his permission, tells a fascinating story. Read on, my friends!
(You can also go ahead and read the original post here.)
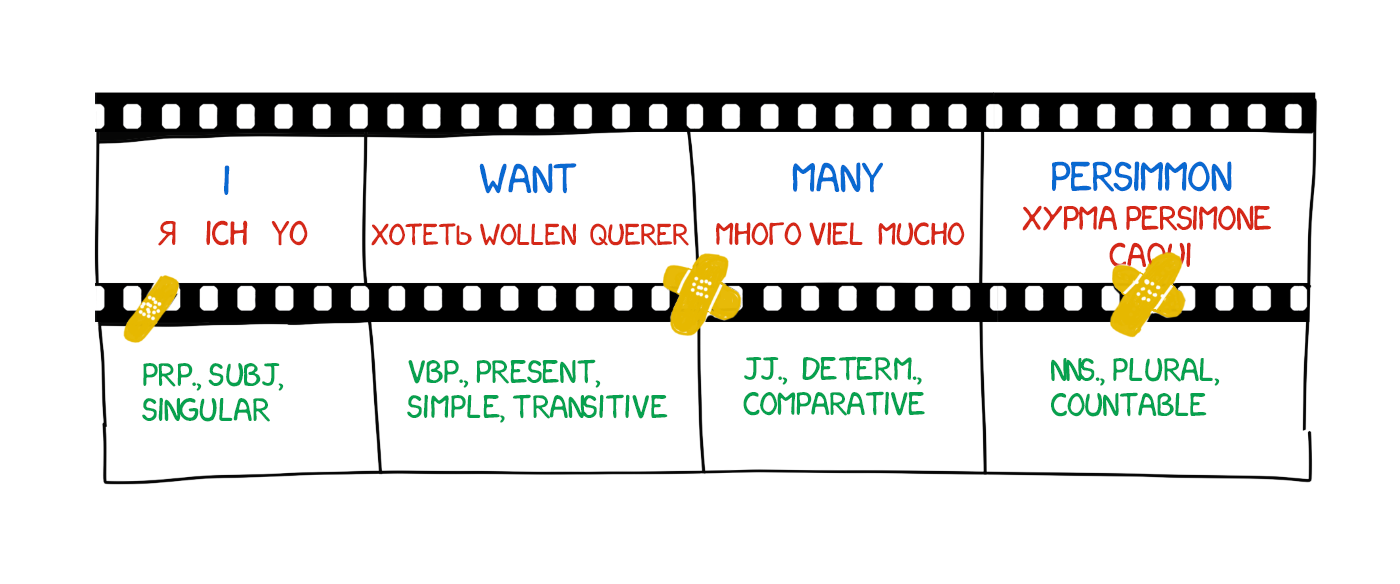
Story begins in 1933. Soviet scientist Peter Troyanskii presented “the machine for the selection and printing of words when translating from one language to another” to the Academy of Sciences of the USSR. The invention was super simple— cards in four different languages, a typewriter, and an old-school film camera.
The operator took the first word from the text, found a corresponding card, took a photo and typed its morphological characteristics (noun, plural, genitive) on the typewriter. The typewriter’s keys encoded one of the features. The tape and the camera’s film were used simultaneously, making a set of frames with words and their morphology.
The resulting tape was sent to linguists and turned into a belletristic text. So only native language was required to work with it. The machine brought the “intermediate language” (interlingua) to life for the first time in history, embodying what Leibniz and Descartes had only dreamed of.
Despite all this, as it had always happened in the USSR, the invention was considered “useless.” Troyanskii died of Stenocardia after trying to finish it for 20 years. No one in the world knew about the machine until two Soviet scientists found his patents in 1956.
It was at the beginning of the Cold War. On January 7th 1954, at IBM headquarters in New York, the Georgetown–IBM experiment started. IBM 701 computer automatically translated 60 Russian sentences into English for the first time in history. “A girl who didn’t understand a word of the language of the Soviets punched out the Russian messages on IBM cards. The ‘brain’ dashed off its English translations on an automatic printer at the breakneck speed of two and a half lines per second” —reported the IBM press release.
However, the triumphant headlines hid one little detail. No one mentioned the translated examples were carefully selected and tested to exclude any ambiguity. For everyday use, that system was no better than a pocket phrasebook. Nevertheless, the Arms Race launched; Canada, Germany, France, and especially Japan, all joined the race for machine translation.
The vain struggles to improve machine translation lasted for forty years. In 1966, the US ALPAC committee, in its famous report, called machine translation expensive, inaccurate, and unpromising. They had instead recommended focusing on dictionary development, which eliminated US researchers from the race for almost a decade.
Even so, a basis for modern Natural Language Processing was created only by the scientists and their attempts, research, and developments. All of today’s search engines, spam filters, and personal assistants appeared thanks to a bunch of countries spying on each other.
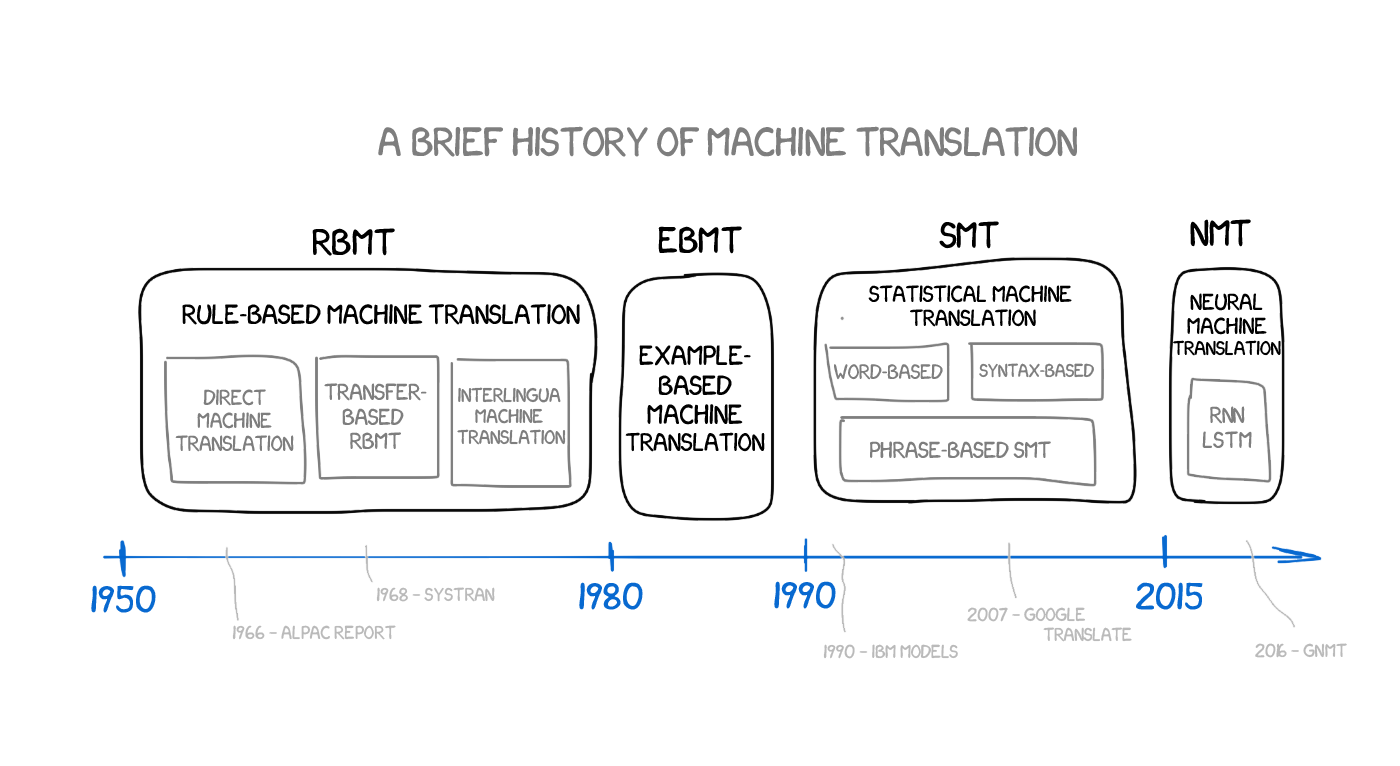
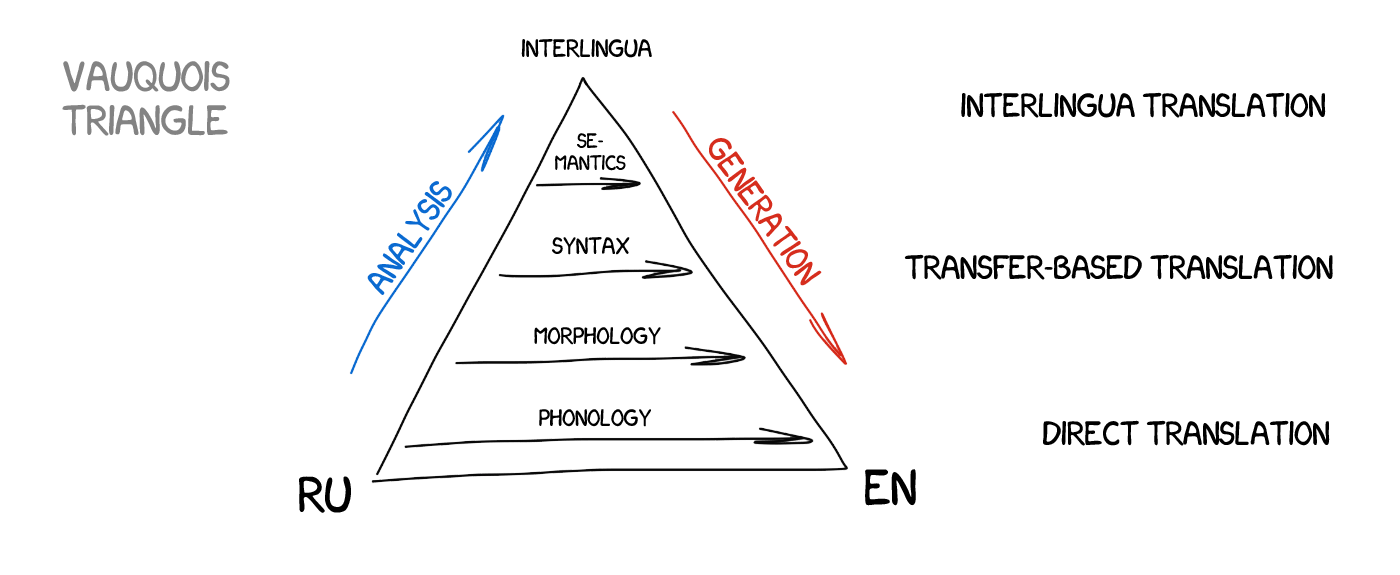
Rule-based Machine Translation (RBMT)
The first ideas of rule-based machine translation appeared in the 70s. The scientists peered over the interpreters’ work, trying to compel the tremendous sluggish computers to repeat those actions. These systems consisted of:
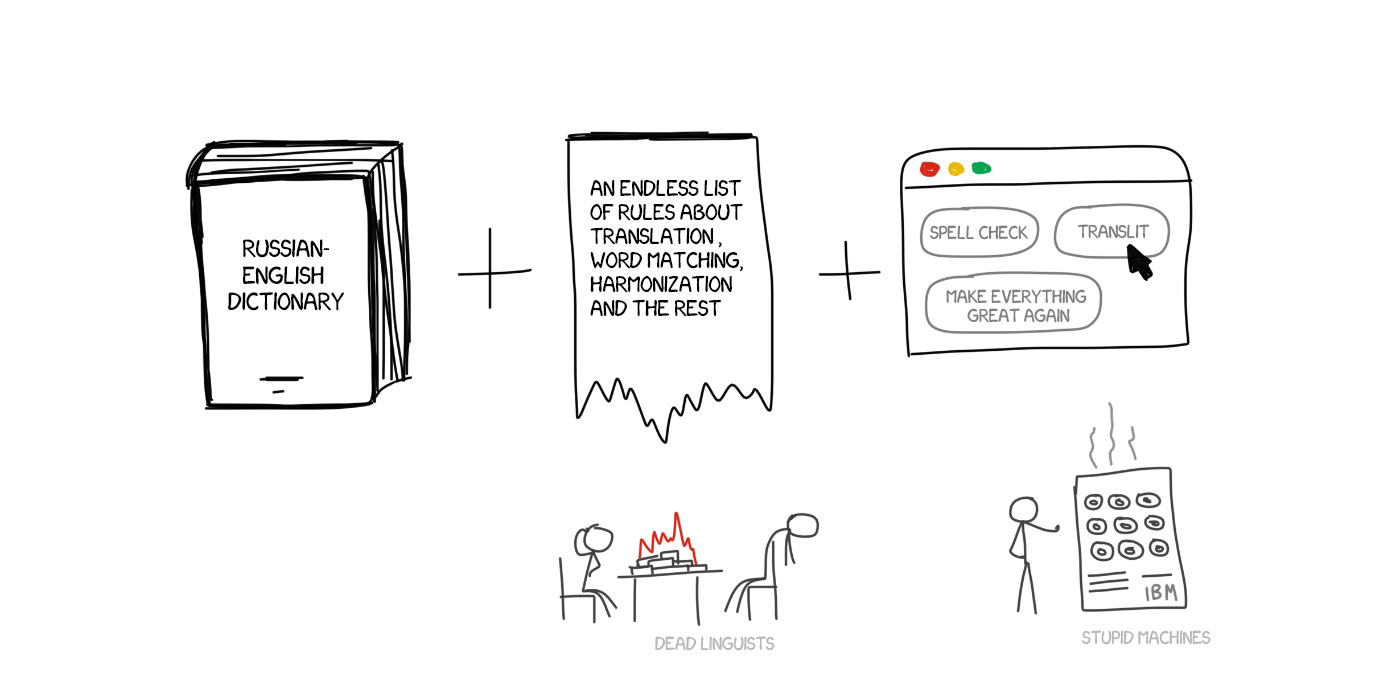
Bilingual dictionary (RU -> EN)
A set of linguistic rules for each language (nouns ending in certain suffixes such as -heit, -keit, -ung are feminine)
That’s it. If needed, systems could be supplemented with hacks, such as lists of names, spell checkers, and transliterators.
PROMPT and Systran are most famous examples of RBMT systems. Just take a look at the Aliexpress to feel the soft breath of this golden age.
But even they had some nuances and subspecies.
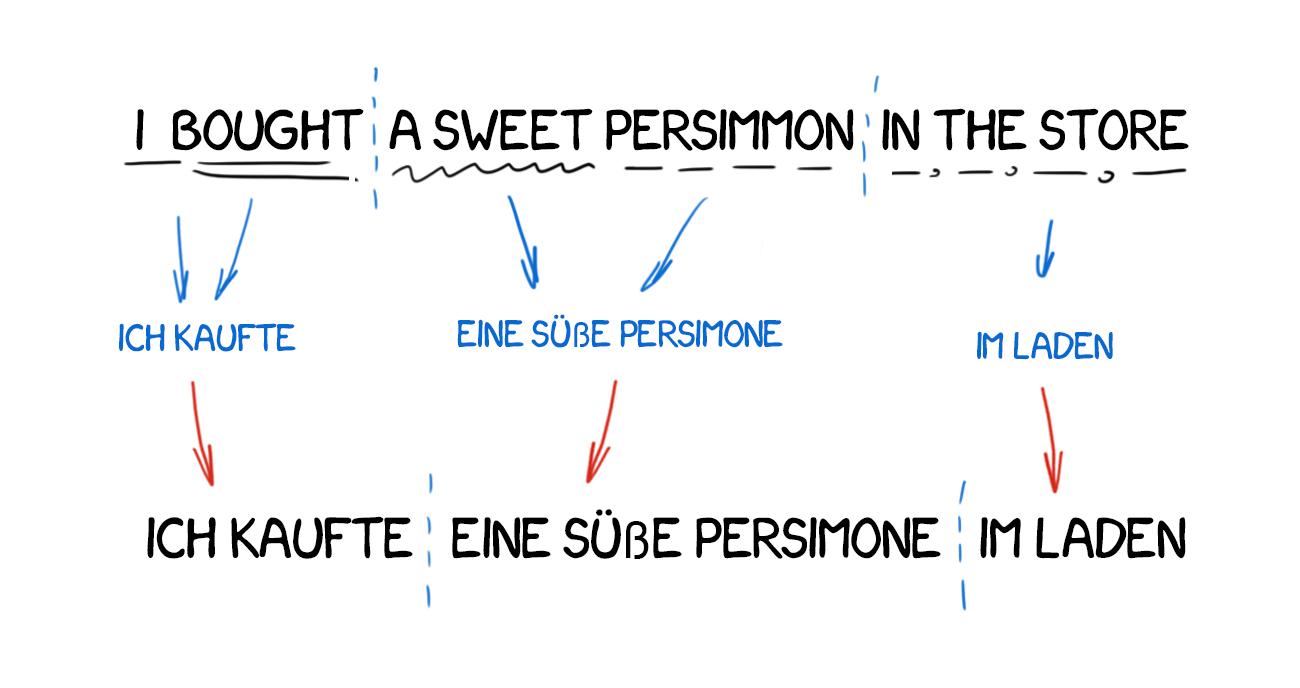
Direct Machine Translation
This is the most straightforward type of machine translation. It divides the text into words, translates them, slightly corrects the morphology, and harmonizes syntax to make the whole thing sound right, more or less. When the sun goes down, trained linguists write the rules for each word.
The output returns some kind of translation. Usually, it’s quite shitty. The linguists wasted for nothing.
Modern systems do not use this approach at all. Linguists are grateful.
Transfer-based Machine Translation
In contrast to direct translation, we prepare first —determining the grammatical structure of the sentence, as we were taught at school—, and manipulate whole constructions, not words — afterwards. That helps to get quite a decent conversion of the word order in translation. In theory. It still resulted in verbatim translation and exhausted linguists in practice.
On one side, it provided simplified general grammar rules, and on the other, it became more complicated because of the increased number of word constructions in comparison with single words.
Interlingual Machine Translation
The source text is transformed to the intermediate representation, unified for all the world languages (interlingua). That’s the same interlingua Descartes dreamed of: a metalanguage, which follows the universal rules and transforms the translation into a simple “back and forth” task. Next, interlingua converts to any target language, and here comes the singularity!
Because of the conversion, interlingua is often confused with transfer-based systems. The difference is the linguistic rules specific to every single language and interlingua, and not language pairs. This means, we can add a third language to the interlingua system and translate between all three, and can’t do the same in transfer-based systems.
It looks perfect, but it’s not, in real life. It was extremely hard to create such universal interlingua —a lot of scientists have worked on it their whole life. They did not succeed, but thanks to them we now have morphological, syntactic, and even semantic levels of representation, only meaning-text theory costs a fortune!
The idea of an intermediate language will be back. Let’s wait awhile.
As you can see, all RBMTs are dumb and terrifying, and that’s the reason they are rarely used unless for specific cases such as weather report translation, etc. Among the advantages of RBMT most often mentioned are its morphological accuracy (it doesn’t confuse words), reproducibility of results (all translators get the same result), and ability to tune it to subject areas (to teach economists or programmers specific terms).
Even if anyone were to succeed in creating an ideal RBMT and linguists enhanced it with all the spelling rules, there are always some exceptions —all the irregular verbs in English, separable prefixes in German, suffixes in Russian, and situations when people just say it differently. Any attempt to take into account all the nuances would waste millions of man-hours.
And don’t forget about homonyms. The same word can have a different meaning in a different context, which leads to a variety of translations. How many meanings can you catch in “I saw a man on a hill with a telescope”?
Languages did not develop based on a fixed set of rules that linguists loved. They were much more influenced by the history of invasions in the past three hundred years. How should I explain that to a machine?
The forty years of the Cold War didn’t help in finding any distinct solution. RBMT was dead.
Example-based Machine Translation (EBMT)
Japan was especially interested in fighting for machine translation. There was no Cold War, but there were reasons: very few people in the country knew English. It promised to be quite an issue at the upcoming globalisation party. So the Japanese were extremely motivated to find a working method of machine translation.
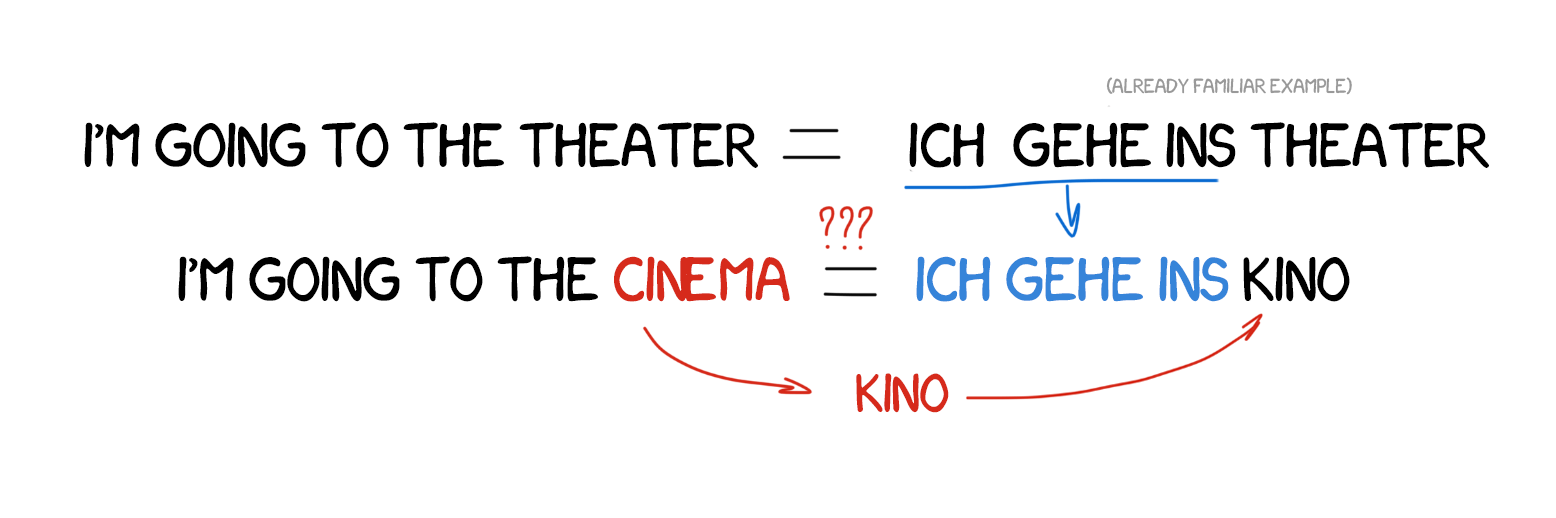
Rule-based English-Japanese translation is extremely complicated —language structure is completely different, almost all words have to be rearranged and new ones added. In 1984, Makoto Nagao from Kyoto University came up with the idea of using ready-made phrases instead of repeated translation.
Let’s imagine, we have to translate a simple sentence— “I’m going to the cinema.” We already translated another similar sentence— “I’m going to the theater,” and we have the word “cinema” in our dictionary. All we need is to figure out the difference between the two sentences, translate the missing word, and then not fuck it up. The more examples we have, the better the translation.
EBMT showed the light of day to scientists from all over the world: it turns out, you can just feed the machine with existing translations and not spend years forming rules and exceptions. Not a revolution yet, but clearly the first step towards it. The revolutionary invention of statistical translation would happen in five years.
Statistical Machine Translation (SMT)
At the turn of 1990, at the IBM Research Center a machine translation system was first shown which knew nothing about rules and linguistics as a whole. It analyzed similar texts in two languages and tried to understand the patterns.
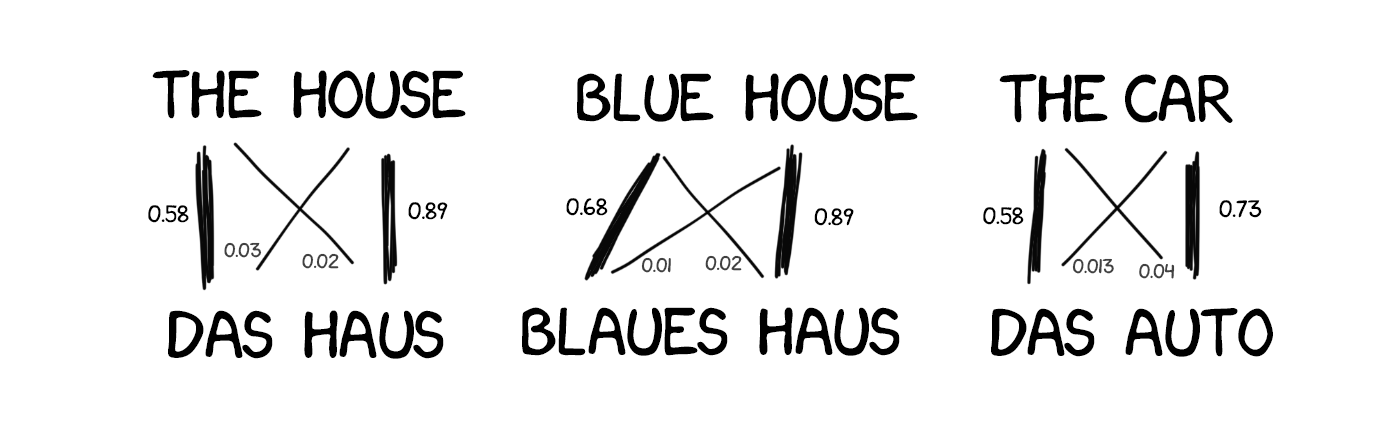
The idea was simple yet beautiful. An identical sentence in two languages split into words, which were matched afterwards. This operation was repeated about 500 million times to count, e.g. how many times the word “Haus” was translated as “house,” “building,” “construction,” etc. If most of the time the source word was translated as “house,” we were using this. Note that no rules were set and no dictionaries were used —all conclusions were drawn by the machine, guided by stats and the logic “If people translate it that way, so will I.” And statistical translation was born.
The method was much more efficient and accurate than all the previous ones. And no linguists were needed. The more texts we use, the better translation we get.
There was still one question left— how does the machine correlate the word “Haus” and the word “building,” and how do we know these are the right ones?
The answer— we don’t. At the start, the machine assumes that the word “Haus” correlates equally with any word from the translated sentence. Next, when “Haus” appears in other sentences, the number of correlations with “house” increases. That’s the “word alignment algorithm,” a typical task for university-level machine learning.
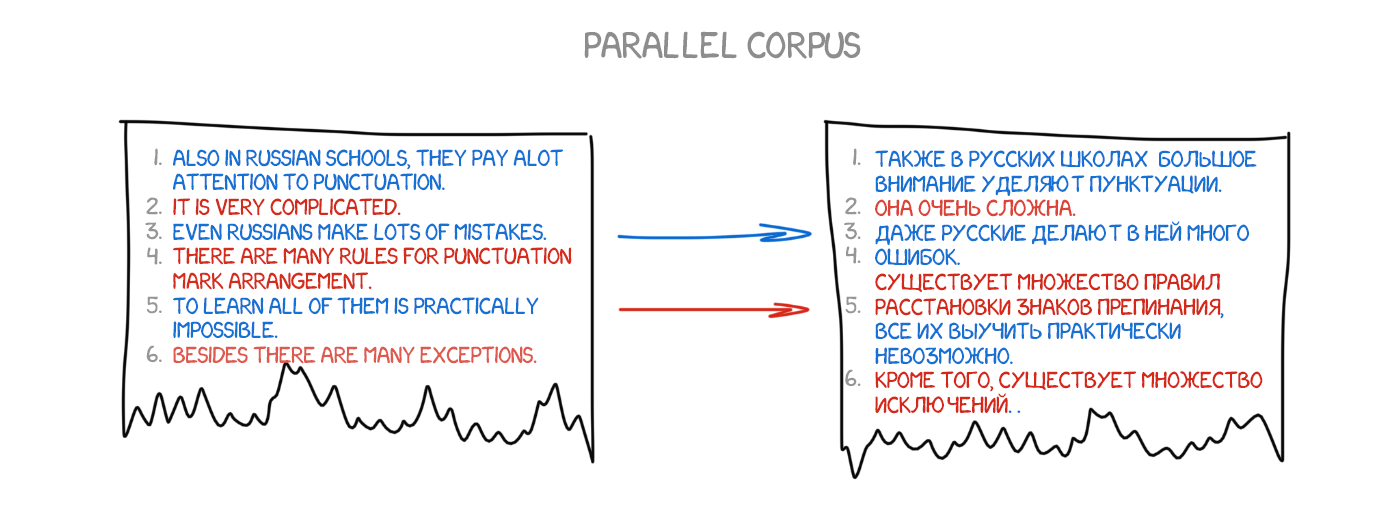
The machine needs millions and millions of sentences in two languages to collect the relevant statistics for each word. How do we get them? Well, let’s just take abstracts of the minutes of the European Parliament and the United Nations Security Council meetings —they are available in the languages of all member countries and are now available for download: UN Corpora and Europarl Corpora.
Google’s statistical translation from the inside. It shows not only the probabilities but also counts the reverse statistics.
Word-based SMT
In the beginning, the first statistical translation systems worked by splitting the sentence into words, as this was straightforward and logical. IBM’s first statistical translation model was called Model One. Quite elegant, right? Guess what they called the second one?
Model 1: “The bag of words”
Model One used a classical approach to split sentences into words and count stats. Word order wasn’t taken into account. The only trick was translating one word into multiple words. E.g. “Staubsauger” could turn into “vacuum cleaner,” but that didn’t mean it would work the same way vice versa.
Here are some simple implementations in Python: [shawa/IBM-Model-1].
Model 2: Considering word order in sentences
The lack of knowledge about word order in languages became a problem for Model 1, a very important one in some cases. Model 2 dealt with that; it memorized the usual place the word takes at the output sentence and shuffled the words for a more natural flow at the intermediate step.
Things got better, still shitty tho.
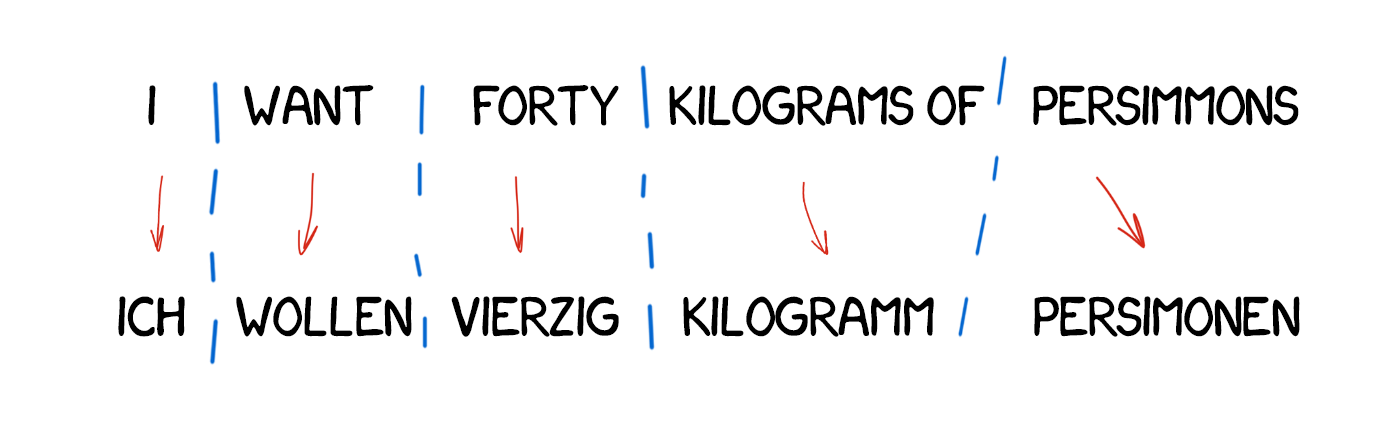
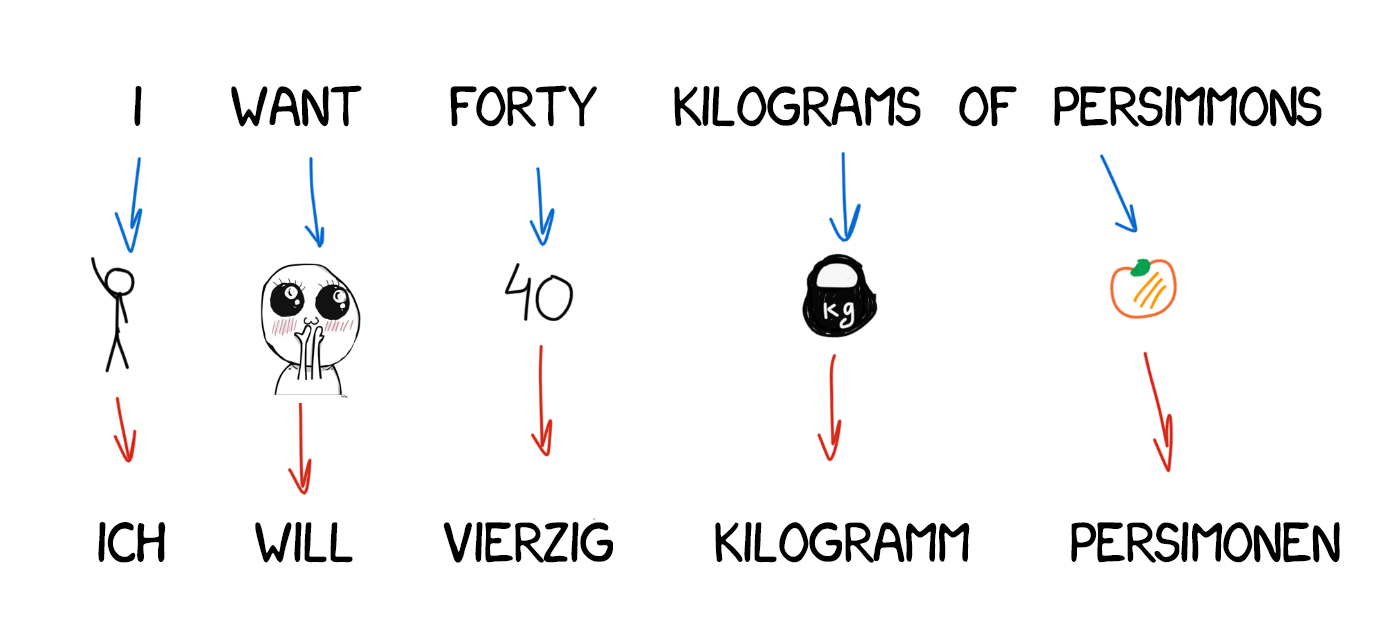
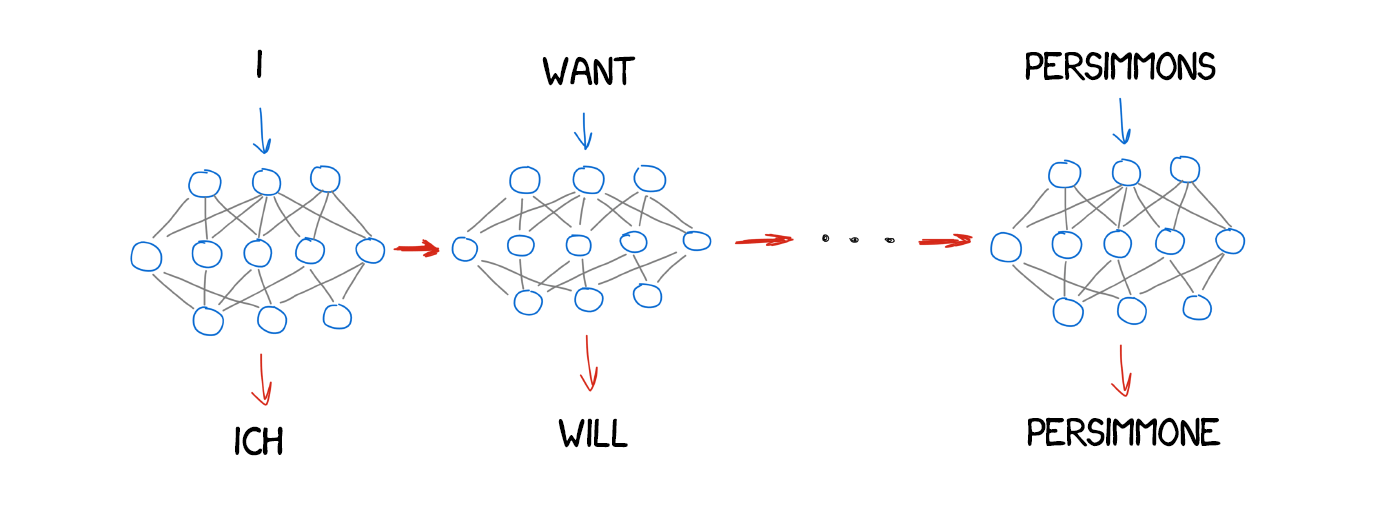
Model 3: Extra fertility
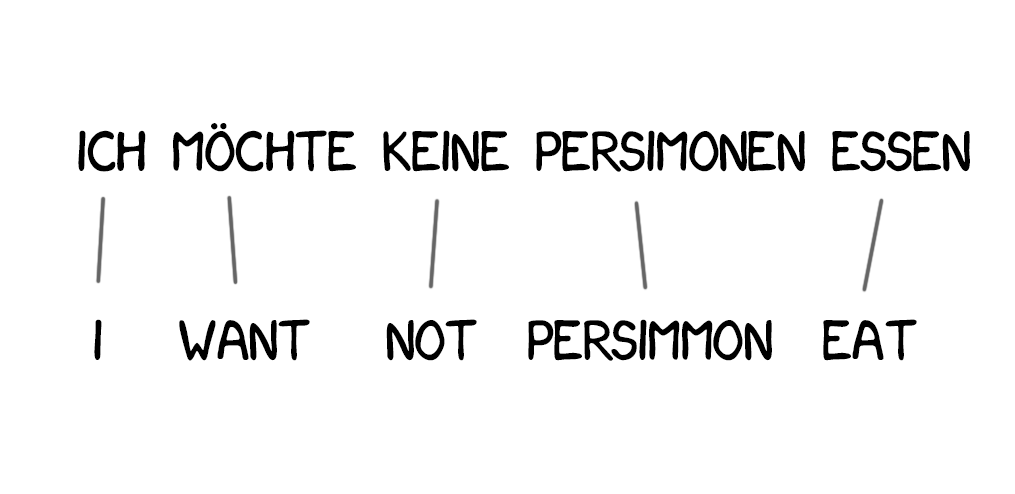
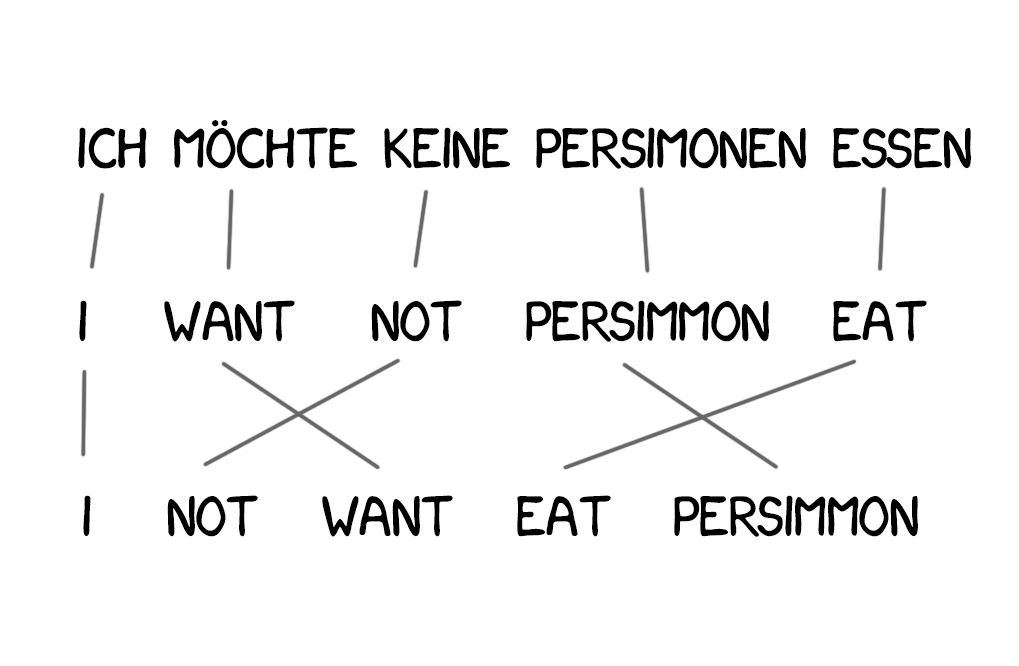
New words appear in the translation quite often, such as articles in German or using “do” when negating in English. “Ich will keine Persimonen” → “I do not want Persimmons.” To deal with it, two more steps were added in Model 3:
NULL token insertion, if the machine considered a new word was needed;
Choosing the right grammatical particle or word for each token-word alignment.
Model 4: Word alignment
Model 2 considered word alignment, but knew nothing about reordering. E.g., adjectives often switch places with nouns, and no matter how good the order is memorized, it won’t make the output any better. Therefore, Model 4 takes into account the so-called “relative order”— i.e., the model learns whether two words always switch places.
Model 5: Bug fixes
Nothing new. Model 5 got some more learning parameters and fixed the issue with conflicting word positions.
Despite its revolutionary nature, word-based systems still failed to deal with cases, gender, and homonymy. Every single word was translated in a single-true way, according to the machine. Such systems are not used anymore, being replaced by the more advanced phrase-based methods.
Phrase-based SMT
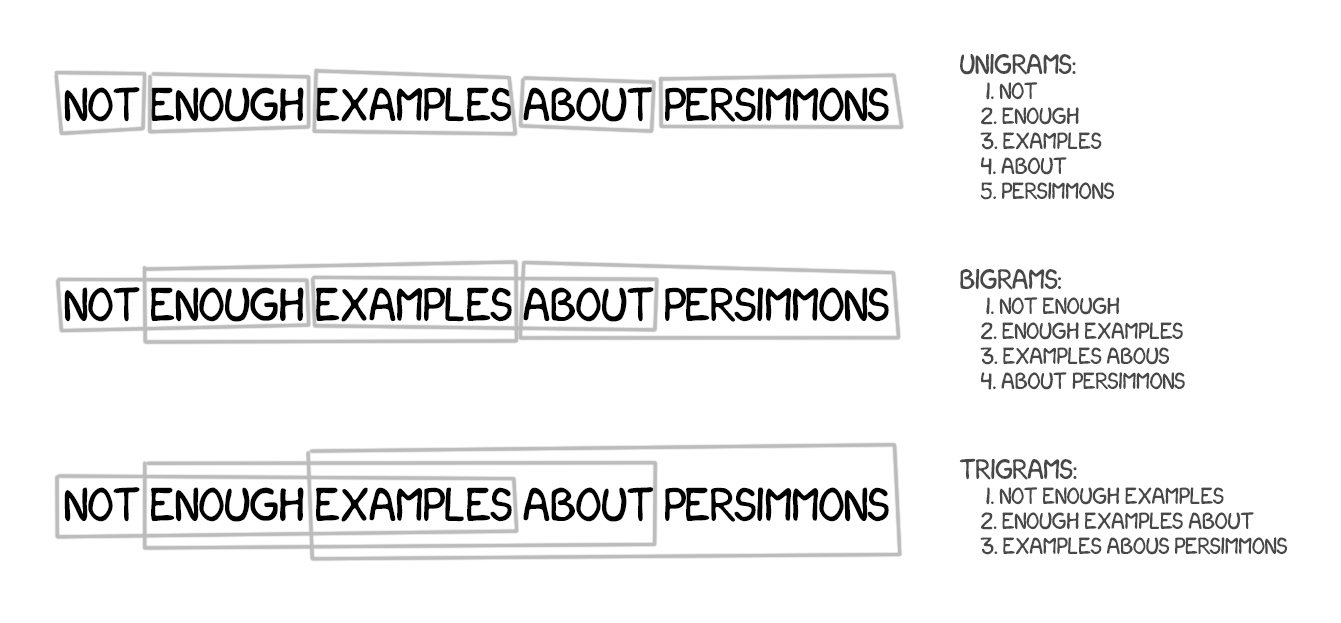
This method is based on all word-based translation principles: statistics, reordering, and lexical hacks, although, for learning, it splits the text not only into words but also into phrases. The n-grams, to be precise, which are a contiguous sequence of n words in a row. Thus, the machine learned to translate steady combinations of words, which noticeably improved accuracy.
The trick is, phrases are not always simple syntax constructions, and the quality of the translation drops significantly if anyone who is aware of linguistics and sentence structure interferes. Frederick Jelinek, the pioneer of computer linguistics, joked about it once: “Every time I fire a linguist, the performance of the speech recognizer goes up.”
Besides improving accuracy, phrase-based translation provided more options in choosing bilingual texts for learning. For word-based translation, the exact matching of sources was critical, which excluded any literary or free translation. Phrase-based translation has no problem learning from them. To improve the translation, researchers even started to parse news websites in different languages for that purpose.
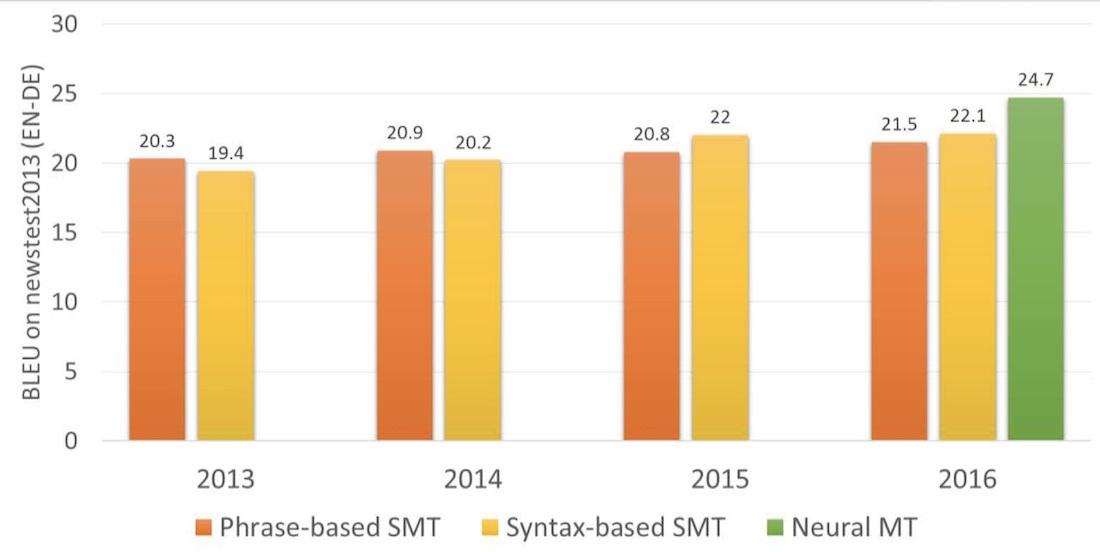
Starting 2006 everyone started to use this approach. Google Translate, Yandex, Bing, and other high-profile online translators worked as phrase-based right until 2016. Each of you can probably recall the moments when Google either translated the sentence flawlessly or resulted in complete nonsense, right? Phrase-based feature.
The good old rule-based approach consistently provided a predictable though terrible result. Statistical methods were surprising and puzzling. Google Translate turns “three hundred” into “300” without any hesitation. That’s called a statistical anomaly.
Phrase-based translation has become so popular that when you hear “statistical machine translation” that is what is actually meant. Up until 2016, all studies lauded phrase-based translation as the state-of-art. Back then, no one even thought that Google was already kindling its stoves to change our whole image of machine translation.
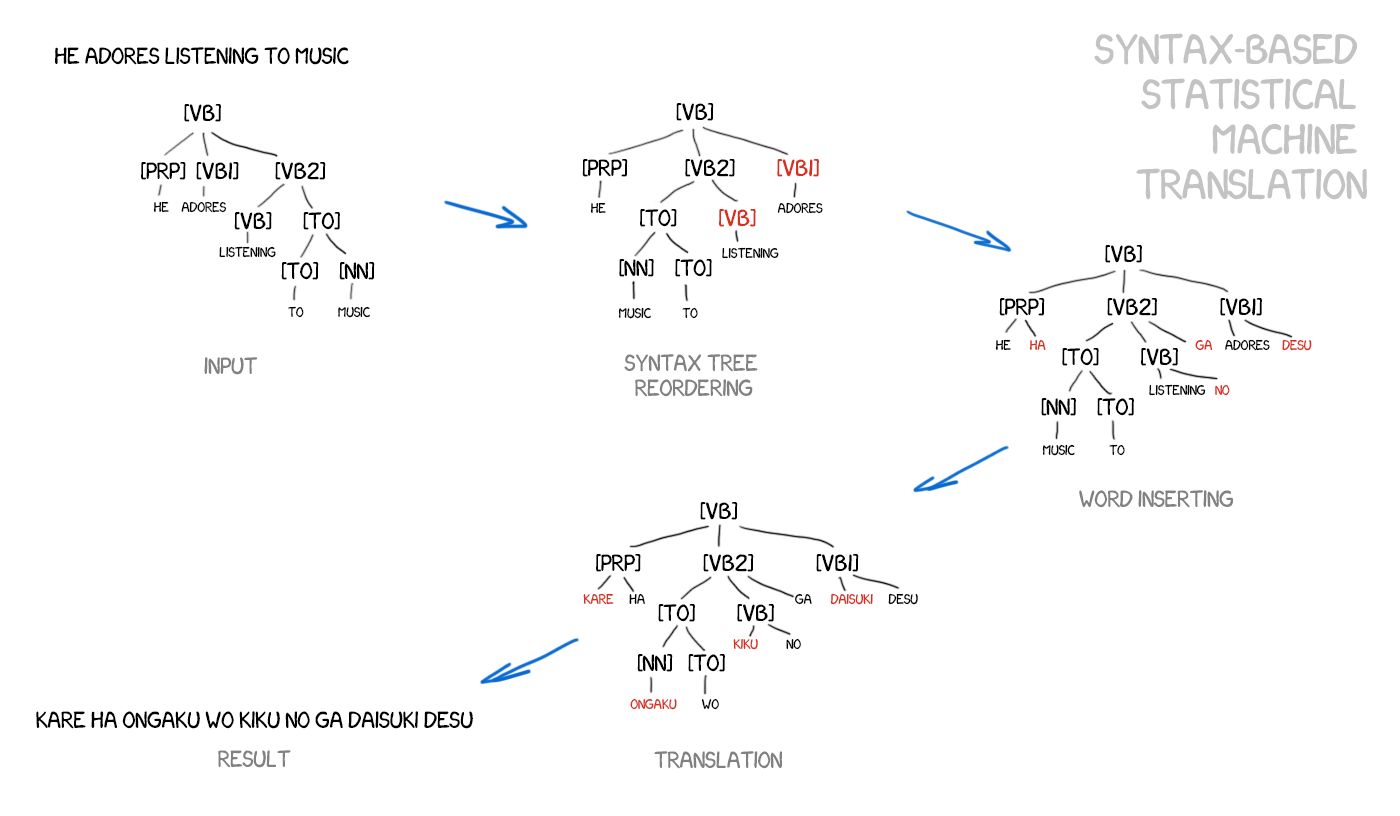
Syntax-based SMT
This method should also be mentioned, briefly. Many years before the emergence of neural networks, syntax-based translation was considered “the future or translation,” but the idea did not take off.
Adepts of syntax-based translation believed in the possibility of merging it with the rule-based method. It’s necessary to do quite a precise syntax analysis of the sentence — to determine the subject, the predicate, other parts of the sentence, and then to build a sentence tree. Using it, the machine learns how to convert syntactic units between languages and translate the rest by words or phrases. That would have solved the word alignment issue once and for all.
Example taken from Yamada and Knight [2001] and this great slide show.The problem is, syntactic parsing works like shit, despite the fact that humanity considered that solved a while ago (as we have ready-made libraries for many languages). I’ve tried to use syntactic trees for tasks a bit more complicated than to parse subject and predicate. And every single time I gave up and used another method.
Neural Machine Translation (NMT)
A quite amusing paper on using neural networks in machine translation was published in 2014. The Internet didn’t notice it at all, except Google —they took out their shovels and started to dig. Two years later, in November 2016, Google made a game-changing announcement.
The idea was close to transferring style between photos. Remember apps like Prisma, which enhanced pics with some famous artist’s style? There was no magic. The neural network was taught to recognize the artist’s paintings. Next, the last layers containing the network’s decision were removed. The resulting stylized picture is just the intermediate image the network got. That’s the network’s fantasy, and we consider it beautiful.
If we can transfer a style to a photo, what if we try to impose another language on the source text? The text would be that precise “artist’s style,” and we’d try to transfer it while keeping the essence of the image (to wit, the essence of the text).
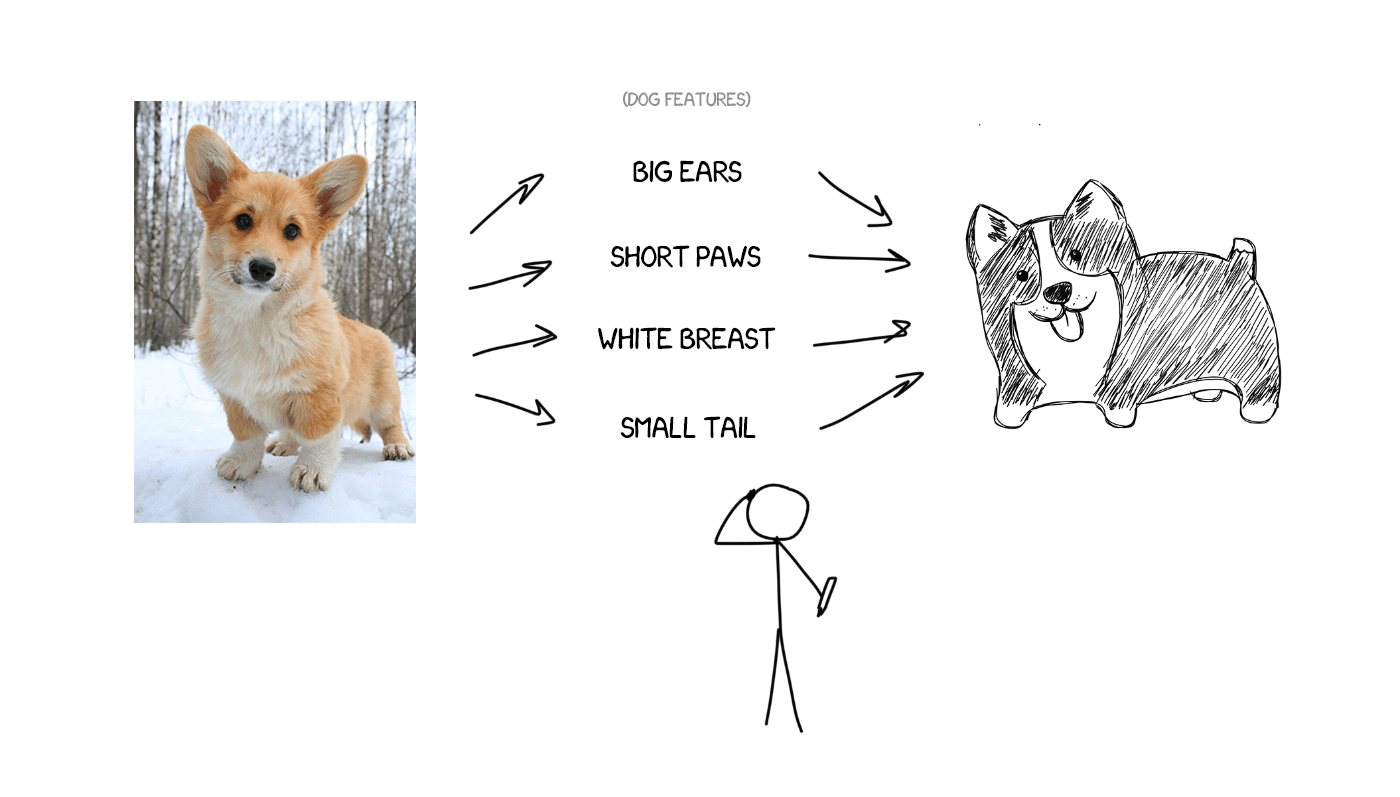
Imagine I’m trying to describe my dog— average size, sharp nose, short tail, always barks. I’ve given you a set of the dog’s features, and if the description is precise, you can draw it, even though you’ve never seen it.
Now, imagine the source text as a set of specific features. Basically, all it takes is to encode it, and let the other neural network decode it back to text, but, in another language. The decoder only knows its language. It has no idea of the origin of the features, but it can express them, e.g., in Spanish. Continuing the analogy, no matter how you draw the dog —with crayons, watercolor, or your finger, you paint it as you can.
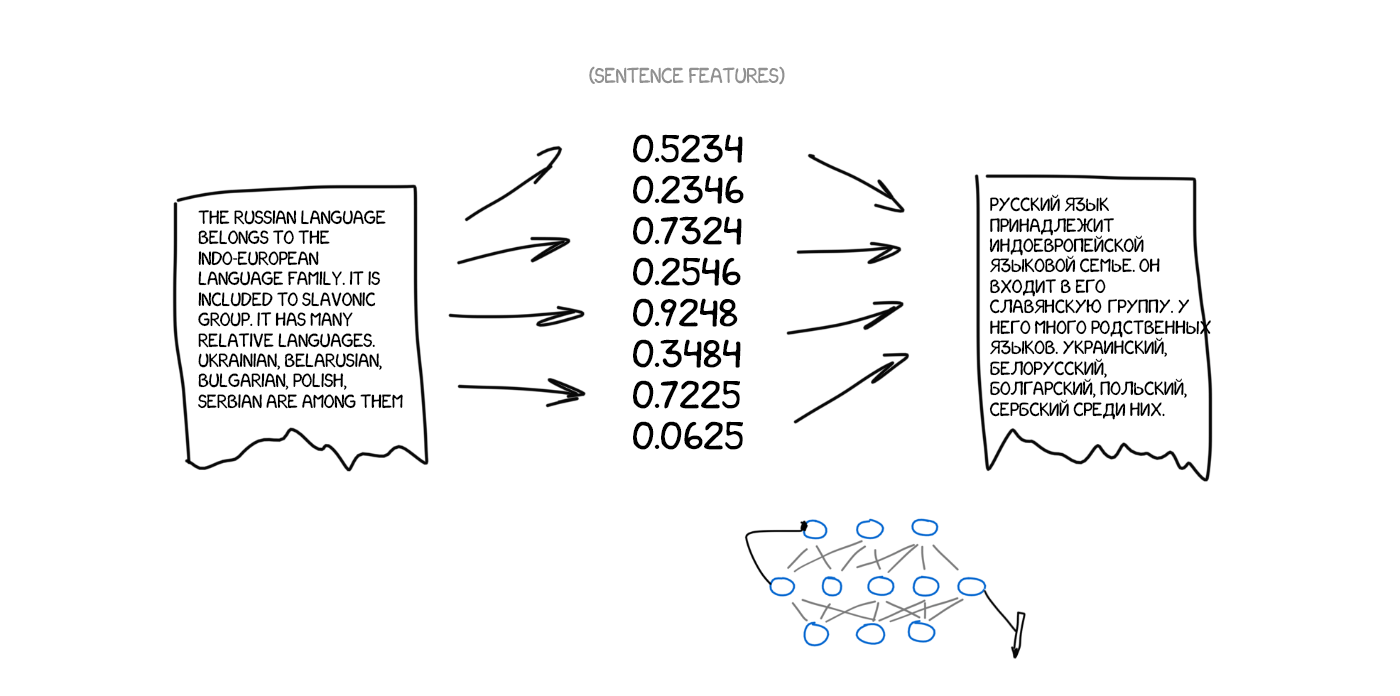
Once again— one neural network can only encode the sentence to a set of features, and another one can only decode them back to text. Both have no idea about each other, and each of them knows only its own language. Recall something? Interlingua is back. Ta-da.
The question is, how to find those features. It’s obvious when we’re talking about the dog, but how to deal with text? Thirty years ago, scientists already tried to create the universal language code, and it ended in a total failure.
Nevertheless, we have deep learning now. And that’s its essential task! The primary distinction between the deep learning and classic neural networks lays precisely in an ability to search for those specific features, without any idea of their nature. If the neural network is big enough and there are a couple thousand video cards at hand, it’s possible to find those features in text as well.
Theoretically, we can pass the features gotten from the neural networks on to the linguists, so that they open brave new horizons for themselves.
The question is, what type of neural network should be used for encoding and decoding. Convolutional Neural Networks (CNN) are a perfect fit for pictures since they operate with independent blocks of pixels. But there are no independent blocks in text; every next word depends on the surroundings. Text, speech, and music are always consistent. So Recurrent Neural Networks (RNN) would be the best choice to handle them, since they remember the previous result —the prior word, in our case.
RNNs are now used everywhere— Siri’s speech recognition (we’re parsing the sequence of sounds, where the next one depends on the previous one), keyboard tips (memorizing the prior one, guessing the next one), music generation, and even chatbots.
Within two years, neural networks surpassed everything that had appeared in the past 20 years of translation. Neural translation contains 50% fewer word order mistakes, 17% fewer lexical mistakes, and 19% fewer grammar mistakes. Neural networks have even learned how to harmonize gender and case in different languages. No one taught them to do so.
The most noticeable improvements occurred in fields where direct translation was never used. Statistical machine translation methods always worked using English as the key source. Thus, if you translated from Russian to German, the machine first translated the text to English and then from English to German, which led to double loss. Neural translation doesn’t need that— only a decoder is required so it can work. It was the first time direct translation between languages with no сommon dictionary became possible.
[You can read the original article for information about Google Translate and Yandex.]
The conclusion and the future
Everyone’s still excited about the idea of the “Babel fish”— instant speech translation. Google steps towards it with its Pixel Buds, but in fact, it’s still not what we were dreaming of. Instant speech translation is different from the usual one. It’s necessary to know when to start to translate and when to shut up and listen. I haven’t seen suitable approaches to solve this yet. Unless Skype…
And here’s one more empty area— all learning is limited to a set of parallel text blocks. The deepest neural networks still learn from parallel texts. We can’t teach a neural network without providing it with a source. People, instead, can complement their lexicon by reading books or articles, even if not translating them into their native language.
If people can do it, the neural network can do it too, in theory. I found only one prototype attempting to incite the network, which knows one language, to read texts in other languages in order to gain experience. I’d try it myself, but I’m silly. Apparently, that’s it.
Forensic scientists collect, analyze, and compare physical evidence from suspected crimes. They provide analysis of evidence in toxicology, including alcohol, controlled substances and clandestine drug labs, biology and DNA, firearms, impression evidence such as shoeprints, tire marks or fingerprints, trace evidence including hair, fibers, and paint, and crime-scene analysis of blood spatter patterns and evidence collection, and they testify in state and federal court cases about their analyses in criminal trials.
If you need to translate documents in the field of forensic analysis, you may find this capsule vocabulary list by Rebecca Jowers most helpful.
In their work ES-EN legal translators (and lawyers and professors) often require a minimum basic vocabulary in a specific area of law, something that they will be hard pressed to find searching word-by-word in a dictionary. (In this case, the “problem” with dictionaries is that they are in alphabetical order!) Blog entries labeled “Capsule Vocabularies” will feature some of the basic terminology lists developed for use by my students of legal English that may also be of interest to translator and interpreter colleagues and other legal professionals.
(Análisis forense) Forensic Analysis
policía científica—forensic police; crime scene investigators
inspección ocular técnico policial—crime scene investigation
El Diccionario Español de Ingeniería es un recurso fantástico de fácil acceso que puede resultar muy útil a la hora de traducir textos técnicos, incluso del campo de la ingeniería biomédica, al español.
El Diccionario Español de Ingeniería se concibe como un gran árbol cuyo tronco es la Ingeniería y del que se desprenden nueve grandes ramas:
Astronáutica, naval y transportes
Agroforestal
Construcción
Tecnologías de la información y las comunicaciones
Seguridad y defensa
Química industrial
Energía
Ingeniería biomédica
Ingeniería general
Estas nueve grandes ramas de la Ingeniería se han dividido en treinta y dos campos para recoger con precisión todas las voces técnicas utilizadas por los ingenieros afines a cada una de ellos.
Han pasado más de diez años desde que empezaron las gestiones para la elaboración del Diccionario y durante los siete últimos años se han analizado 120 millones de palabras, se han utilizado unas 1500 obras de referencia y han participado más de 100 ingenieros y expertos en los distintos campos de la Ingeniería con el apoyo de un equipo lexicográfico dotado de los mejores medios tanto personales como materiales.
Esta primera edición del Diccionario Español de Ingeniería incluye más de 50.000 voces de la Ingeniería pero, al igual que la lengua de la que se alimenta, es una obra viva que se irá actualizando a medida que surjan nuevos avances tecnológicos y con ellos nuevos términos.
Se trata de un repertorio que recoge vocablos de cada una de las disciplinas que forman la Ingeniería y que además es pionero en accesibilidad y usabilidad.
El Libro de estilo interinstitucional de la Unión Europea contiene las normas y convenciones de redacción que deben utilizar las instituciones, los órganos y los organismos descentralizados de la Unión Europea. Está elaborado por los diferentes grupos de trabajo de las instituciones, que reúnen a representantes de los principales servicios lingüísticos (juristas-lingüistas, traductores, terminólogos, correctores, etc.) y se encuentra disponible en veinticuatro lenguas de la Unión Europea.
La primera parte contiene las normas de estricta aplicación para la redacción de los actos publicados en el Diario Oficial de la Unión Europea, mientras que en la segunda figuran las principales normas técnicas y de redacción relativas a las publicaciones de carácter general. La tercera parte contiene las convenciones comunes a todas las lenguas, y la cuarta, las convenciones específicas de cada lengua.
Puedes consultar la versión electrónica del Libro o descargarlo en formato PDF aquí.
Botis fue la primera traductora robótica. La Compañía había decidido dotarla de apariencia femenina, aunque nunca se supo bien por qué. Era de una belleza tradicional, naturalmente delgada, estilizada y atlética, el cabello siempre perfecto, los ojos nunca cansados, la espalda nunca dolorida.
Llevaba un traje de titanio ligero y resistente que había acabado con uno de los debates más generalizados entre los traductores del siglo XXI; no más discusión con respecto a piyamas sí o piyamas no. Como la comida y la bebida le eran indiferentes, el consumo excesivo de café y comida chatarra que había caracterizado a muchos de sus antecesores humanos había dejado de ser un problema. Tampoco necesitaba dormir ni descansar ni hacer pausas ni tomarse vacaciones… algo impensable años atrás.
Aunque era solo un prototipo, sus redes neuronales, algoritmos informáticos inspirados en el cerebro humano, ya eran capaces de traducir a una velocidad extraordinaria. Traía instaladas todas las memorias de traducción recopiladas a lo largo de la historia y la versión premium del conjunto de programas Ventanas de Oficina, y podía resolver los fallos catastróficos que continuaban ocurriendo a pesar de la gran evolución tecnológica que había transformado el mundo moderno. De hecho, era de total propiedad de Microsoluciones en Ventanas, la compañía que, con sus soluciones automáticas, había llegado a dominar gran parte del mercado de traducción conocido universalmente como low-cost.
Lo único que desconcertaba a Botis era por qué, pese a todo, aquellos traductores humanos seguían viniendo todas las mañanas a instalarse a su lado para revisar sus traducciones. ¡Sus traducciones! A sus campos de especialización individuales habían agregado la posedición de traducciones automáticas. Y los escuchaba hablar enfáticamente de años de estudio y de experiencia de trabajo y capacitación que, según ellos, les permitían tener lo que se empeñaban en llamar “criterio”. Pero de eso, claro, ella no entendía nada.
Activate the service with the IATE Term lookup slider, and select domain. Then you’ll be able to get the IATE search result directly from the text you are reading.
Il traduttore senza cuore (Un piccolo esercizio di traduzione)
When Tiziana Raffa volunteered to translate The heartless translator, a short story, into Italian and Chiara Bartolozzi agreed to edit/proofread her translation, I was far from imagining how fulfilling and joyful the experience would be. They are both the nicest people to work with, and I think these two lovely translators enjoyed working together and exchanging views and opinions.
You can see the Italian team’s work below (in green font), following the English source (in Italics), and the Spanish translation (in blue font).
I hope you enjoy the reading and look forward to seeing this piece translated into other languages as well!
The Heartless Translator | El traductor sin corazón | Il traduttore senza cuore
Once upon a time, there was this poor translator with a worn-out heart.
Había una vez un pobre traductor con el corazón maltrecho.
C’era una volta un povero traduttore dal cuore malconcio.
After living a thousand loaned lives and riding the frantic roller coaster of getting into and out of the skin of a myriad of characters penned and fleshed out by others, after spending a thousand sleepless nights and dreaming of unsolvable ambiguities and impossible deadlines when he did get some sleep, the fibers of his heart had gotten threadbare.
Después de vivir mil vidas ajenas y de subirse innumerables veces a la frenética montaña rusa que supone meterse debajo de la piel de incontables personajes creados y narrados por otros, después de pasar mil y una noches en vela y de soñar con ambigüedades insalvables y plazos de entrega imposibles cuando —por fin— conseguía dormir un poco, las fibras de su corazón estaban deshechas.
Dopo aver vissuto migliaia di vite prese in prestito e aver più volte montato sulle frenetiche montagne russe indossando e togliendo i panni di una miriade di personaggi creati e illustrati da altri, dopo aver trascorso migliaia di notti insonni e aver avuto gli incubi a causa di irrisolvibili ambiguità e impossibili scadenze, quando finalmente riusciva a prendere un po’ di sonno, le fibre del suo cuore erano ridotte allo stremo.
Doctors were helpless at fixing such a life-threatening problem, until one of them came up with the idea of the clockwork machine.
Los médicos no habían podido remediar esta afección que estaba poniendo fin a su vida hasta que a uno de ellos se le ocurrió la idea de recurrir a un mecanismo de relojería.
Nessun medico era in grado di risolvere questo problema che stava mettendo a repentaglio la sua vita, finché uno di loro ebbe l’idea di ricorrere a un meccanismo di orologeria.
It was implanted right inside the hollow space that used to hold his heart, and it started working right away—tick, tack; tick, tack.
Se lo implantaron directamente en el hueco que solía ocupar el corazón, y el aparato comenzó a funcionar de inmediato con su rítmico tic-tac, tic-tac.
Glielo impiantò direttamente nello spazio vuoto dove un tempo era situato il cuore e il meccanismo iniziò immediatamente a funzionare: tic, tac; tic, tac.
The translator soon recovered his health, but never got his magic back.
El traductor pronto recuperó la salud, pero sus palabras nunca recuperaron la magia.
Il traduttore riacquistò subito la salute, ma non recuperò più la magia delle sue parole.
He was still able to translate to the best of his mind, but he was missing a heart.
Seguía poniendo toda su inteligencia al servicio de su trabajo… pero, ahora, le faltaba corazón.
Era ancora in grado di tradurre dando il meglio di sé con la mente, ma si ritrovava senza più un cuore.
And a heart is not something a translator can do without.
Y corazón es algo que a un traductor no puede faltarle.
E il cuore è qualcosa di cui un traduttore non può fare a meno.
Meet the Italian Translator: Tiziana Raffa
Tiziana has worked as a freelance translator and interpreter EN/ES>IT since 2012. She has a Bachelor’s Degree in Translation and Interpreting and a Master’s Degree in Modern Languages for International Communication. She has also earned a 1st Level Master’s Degree in Translation and Interpreting at the SSML “Gregorio VII” (Advanced School of Modern Languages for Interpreters and Translators) in Rome and a Master’s Degree in Audiovisual Translation: Localisation, Subtitling and Dubbing at the Instituto Superior de Estudios Lingüísticos y Traducción in Seville. As an interpreter, she has taken part in various conferences in Rome. She is currently working as a freelance audiovisual translator and proofreader for Studio Asci in Crema, a small town in the north of Italy, and for Grupo Mediapro and P4 Traducciones, two audiovisual translation agencies in Seville. You can find her on Twitter and LinkedIn.
And the Italian Proofreader: Chiara Bartolozzi
Chiara is a freelance professional translator, interpreter and a copywriter-to-be owner of One Sec Translations. She translates from English, Spanish and (Simplified) Chinese into Italian. Although her specialisations are fashion, journalism, tourism and advertising, she also currently translates technical and legal documents from English and Spanish. Cinema and TV series addict, music lover, she deeply loves the English language and its culture as much as the Eastern one.